|
I am a researcher on multi-modal intelligence. I studied computer science at University of Illinois Urabana-Champaign (UIUC) as a Ph.D. student and Peking University (PKU) as an undergraduate student. I build multi-modal intelligence with the both capabilities of generation and understanding in my mind, connecting the components of representation, pixels, language, and actions. I have built and studied: Multi-modal agents (Lux ), Generative Foundation Models Unifying Generation and Understanding (RandAR, ADDP, LM4VE) and Understanding & Reasoning (Long) Videos (GLUS, MR. Video, XComp , RMem, PF-Track) for multi-modal understanding and agents. Actively seeking full-time jobs as a new-grad Ph.D. |

|
|
|
|
|
Main Builder as Founding Research Scientist Project Page Working on data, modeling, infra, eval, and product of Lux. Achieving 72.3% on OnlineMind2Web and 58.8% on OSWorld, at the level of Claude Sonnet-4.5 with much lower costs. |
|
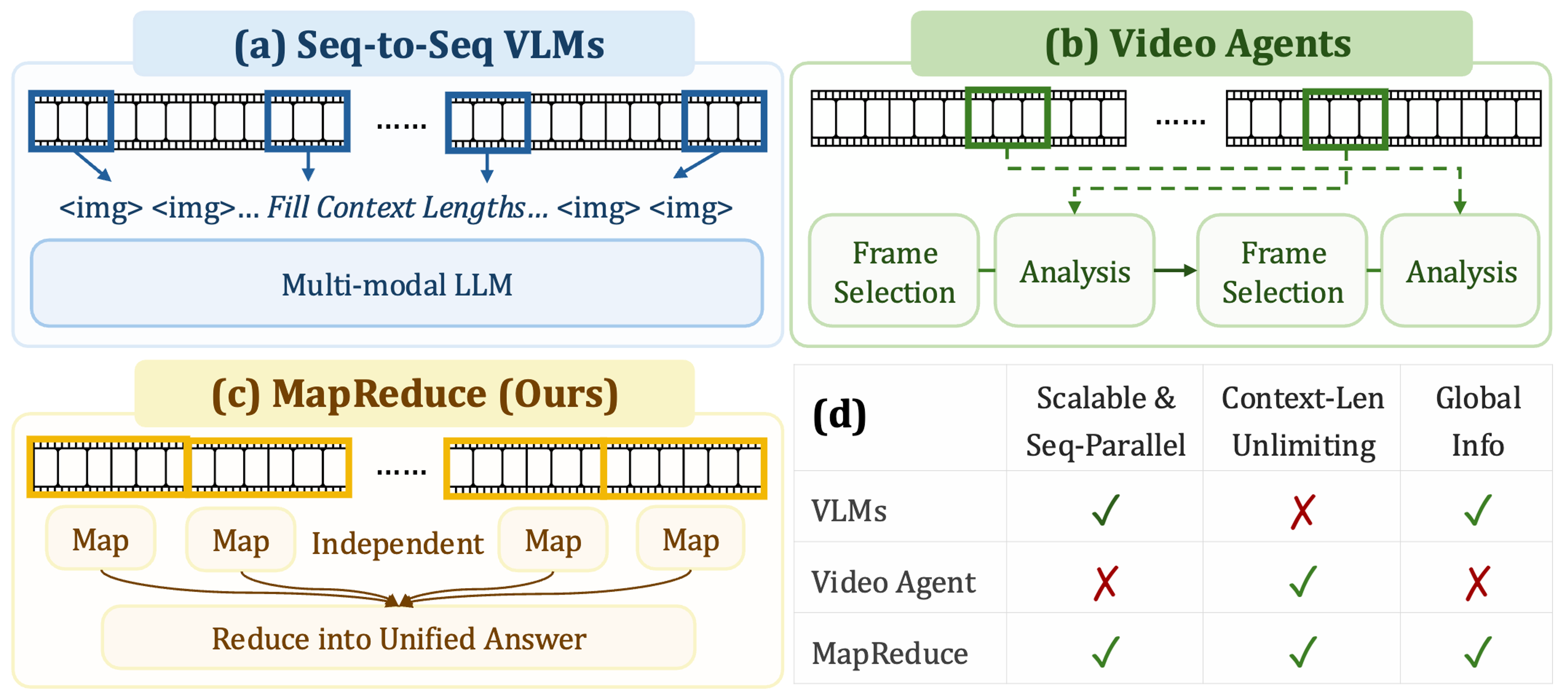 |
Ziqi Pang, Yu-Xiong Wang NeurIPS 2025 Code / arXiv First-principle for long video understanding agents - MapReduce - independent understanding of short segments (system 1) and global reasoning over the whole video (system 2) - performance advantages and scalability guarantee. |
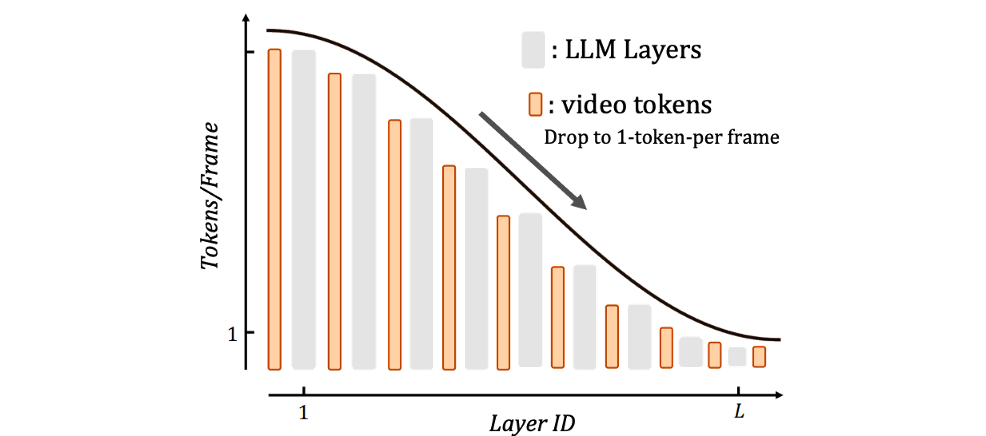 |
Zheyu Zhang, Ziqi Pang, Shixing Chen, Xiang Hao, Vimal Bhat, Yu-Xiong Wang NeurIPS 2025 Code / arXiv Adaptive token compression via training the compression behavior into LLM layers for long video understanding. |
 |
Ziqi Pang*, Tianyuan Zhang *, Fujun Luan , Yunze Man , Hao Tan , Kai Zhang , William T. Freeman , Yu-Xiong Wang CVPR 2025 (Oral) Project Page / Code / arXiv We enable a GPT-style causal transformer to generate images in random orders, which unlocks a series of new capabilities for decoder-only autoregressive models. |
 |
Lang Lin*, Xueyang Yu*, Ziqi Pang*, Yu-Xiong Wang CVPR 2025 Project Page / arXiv / Code We propose a simple yet effective MLLMs for language-instructed video segmentation. It emphasizes global-local video understanding and achieves SOTA performance on multiple benchmarks. |
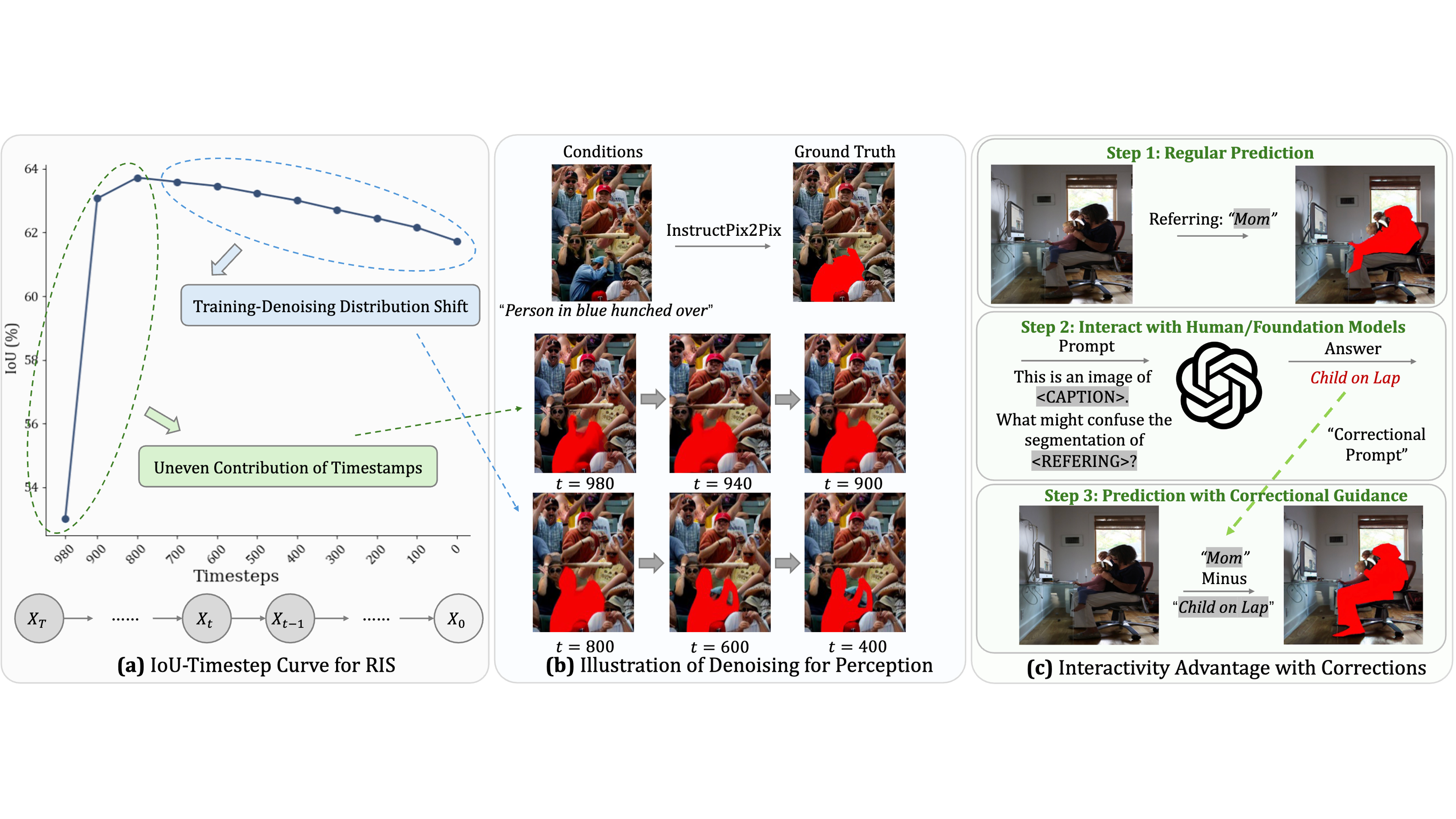 |
Ziqi Pang*, Xin Xu*, Yu-Xiong Wang ICLR 2025 arXiv / Code Our paper answers several critical question on diffusion models for visual perception: (1) how to train diffusion-based perception models, (2) how to utilize diffusion models as a unique interactive user interface. |
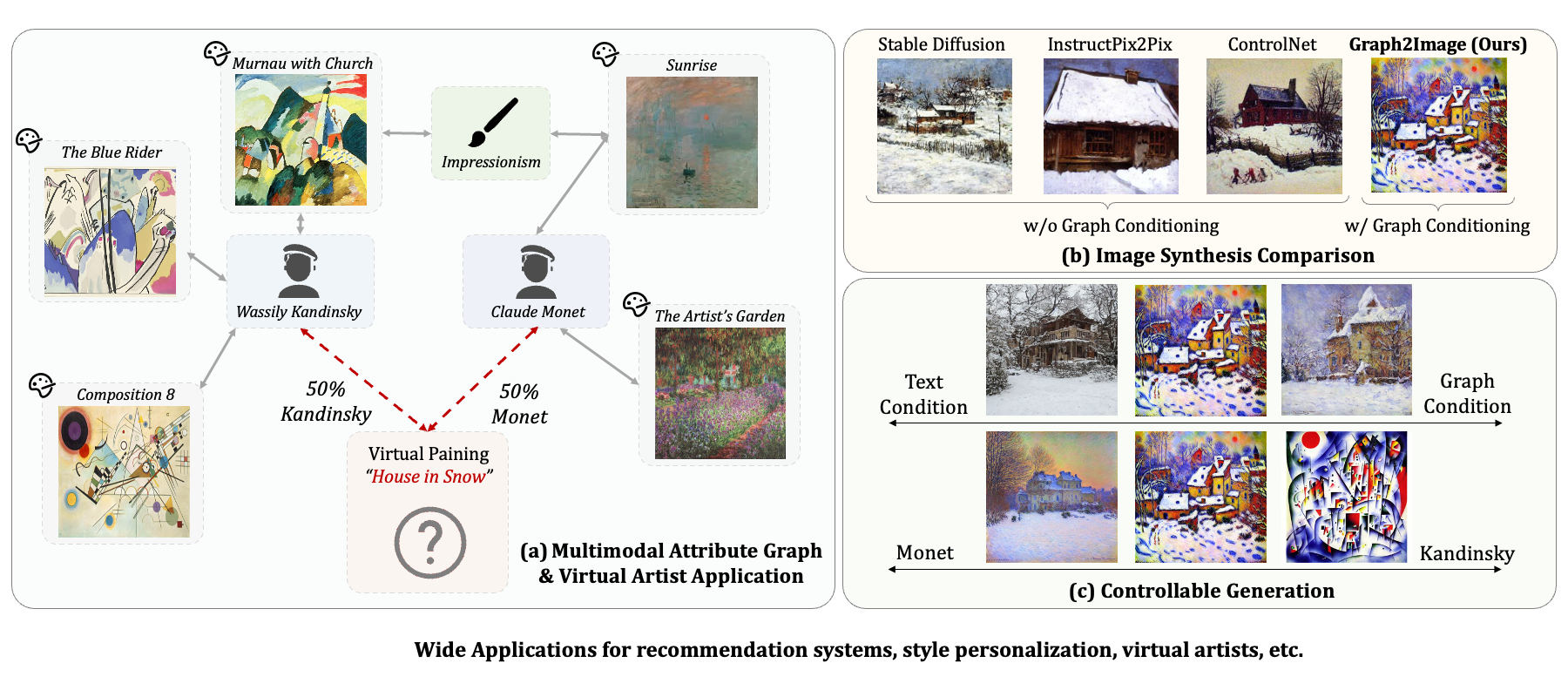 |
Bowen Jin, Ziqi Pang, Bingjun Guo, Yu-Xiong Wang, Jiaxuan You, Jiawei Han NeurIPS 2024 Project Page / Code / arXiv Using the relationships between entities, we can better control the generation of images with multi-modal graphs. |
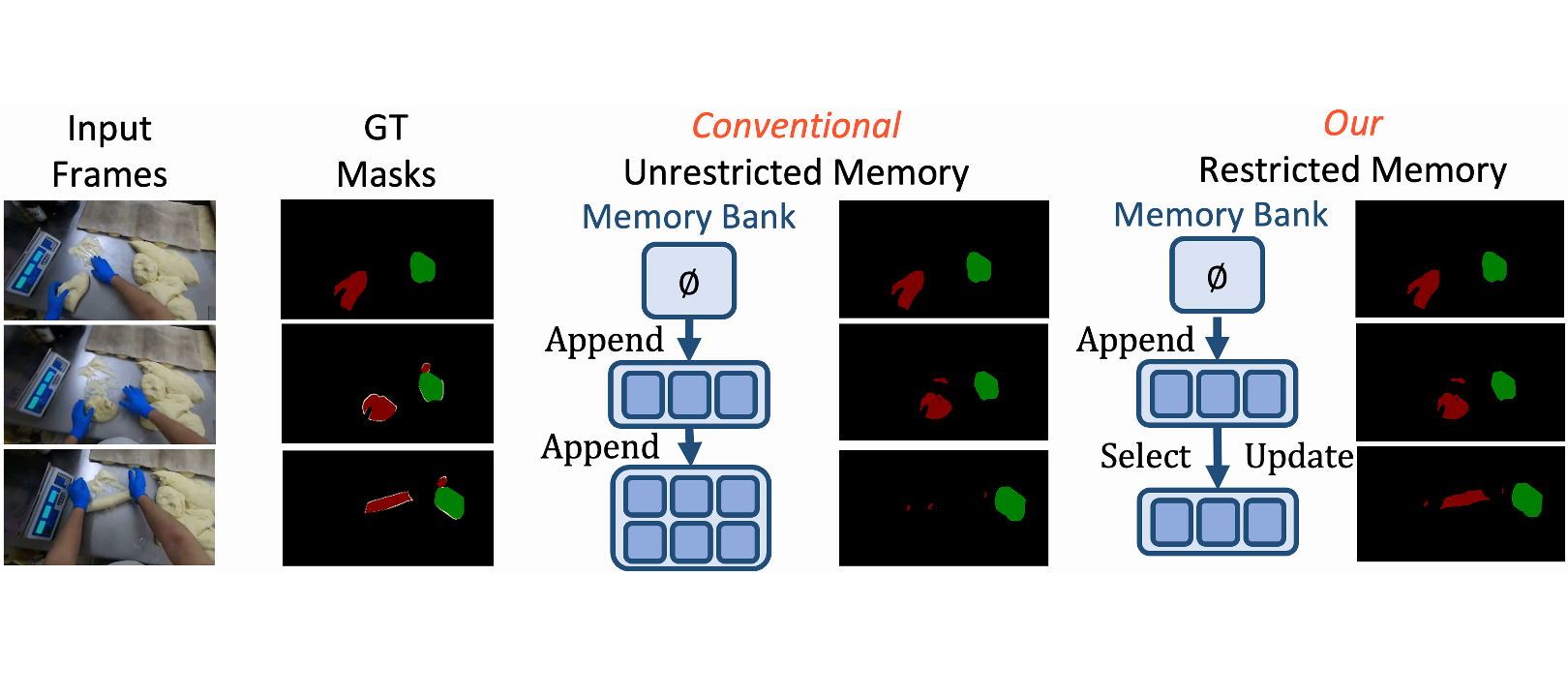 |
Junbao Zhou*, Ziqi Pang*, Yu-Xiong Wang CVPR 2024 (Winner at ECCV 2024 VOTS Challenge) Project Page / Code / arXiv Managing memory banks better significantly improves VOS on challenging state-changes and long videos. Similar strategy is also adopted in SAM2 later. |
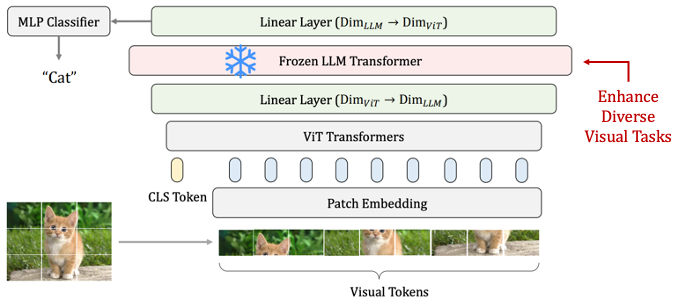 |
Ziqi Pang, Ziyang Xie*, Yunze Man*, Yu-Xiong Wang ICLR 2024 (Spotlight) Code / arXiv Frozen transformers from language models, though trained solely on textual data, can effectively improves diverse visual tasks by directly encoding visual tokens. It is an essential step for my research on "generative models benefiting perception." |
 |
Ziyang Xie*, Ziqi Pang*, Yu-Xiong Wang ICCV 2023 Code / arXiv / Demo MV-Map is the first offboard auto-labeling pipeline for HD-Maps, whose crust is to fuse BEV perception results guided by geometric cues from NeRFs. |
 |
Ziqi Pang, Deva Ramanan, Mengtian Li, Yu-Xiong Wang IROS 2023 Code / arXiv / Demo "Streaming forecasting" mitigates the gap between "snapshot-based" conventional motion forecasting and the streaming real-world traffic. |
 |
Ziqi Pang, Jie Li, Pavel Tokmakov, Dian Chen, Sergey Zagoruyko, Yu-Xiong Wang CVPR 2023 Code / arXiv / Demo PF-Track is an vision-centric 3D MOT framework that dramatically decreases ID-Switches by 90% with an end-to-end framework for autonomous driving. |
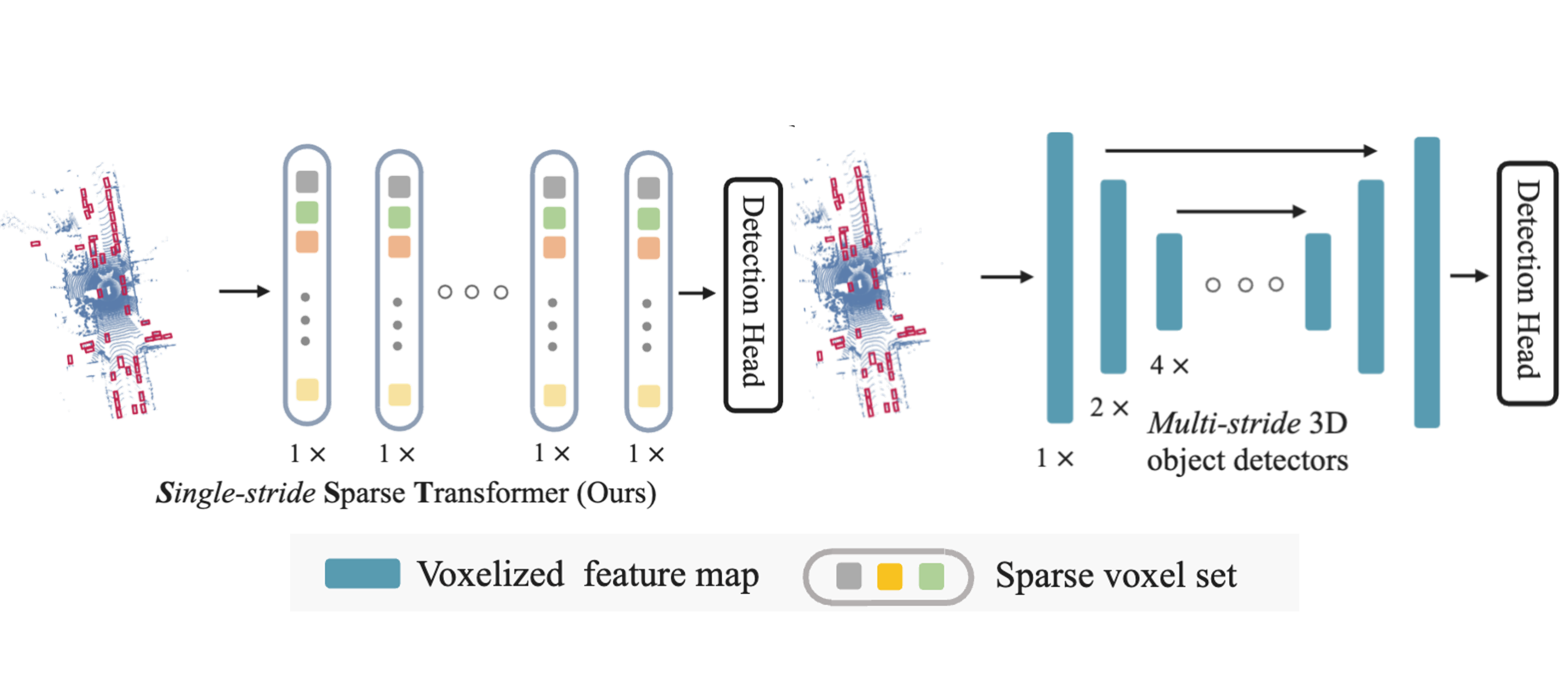 |
Lue Fan, Ziqi Pang, Tianyuan Zhang, Yu-Xiong Wang, Hang Zhao, Feng Wang, Naiyan Wang, Zhaoxiang Zhang CVPR 2022 Code / arXiv SST emphasize the small object sizes and sparsity of point clouds. Its sparse transformers enlight new backbones for outdoor LiDAR-based detection. |
 |
Ziqi Pang, Zhichao Li, Naiyan Wang ECCV Workshop 2022 Code / arXiv / Patent SimpleTrack is simple-yet-effective 3D MOT system. It is one of the most widely adopted 3D MOT baseline worldwide. |
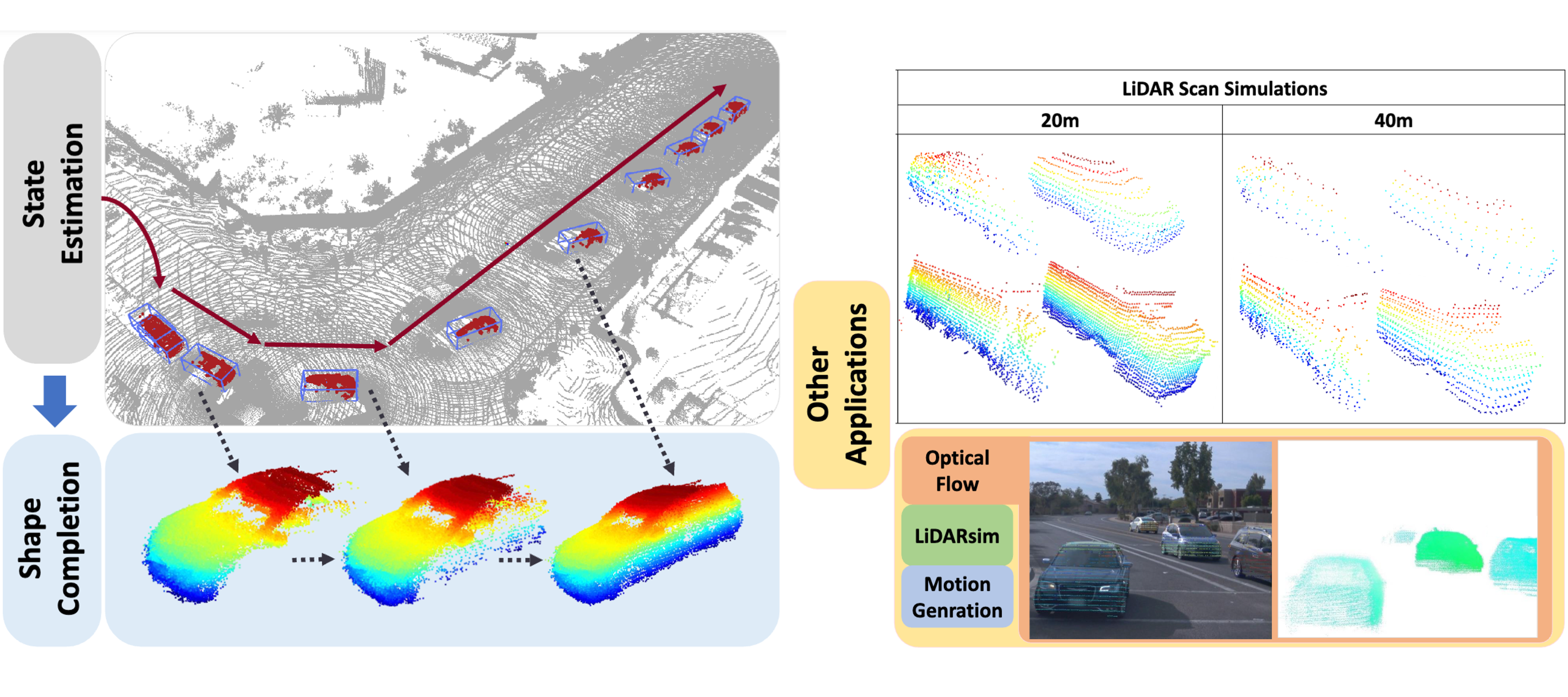 |
Ziqi Pang, Zhichao Li, Naiyan Wang IROS 2021 Code / arXiv / Demo LiDAR-SOT is a LiDAR-based data flywheeel and auto-labeling pipeline for autonomous driving. |
|
Huge thanks to Jon Barron for proving the template for the page. |